轉简體
復原
第一章 基因工程
第一章 基因工程
基因Gene一詞原為希臘文,意思為「生」,指攜帶遺傳訊息的物質。於有性生殖時,性細胞經過染色體的減數分裂,再由陰陽兩性結合還原為一。新生命誕生後,不僅可保持兩代之間之相同性,且能形成逐代的演變進化。其生命訊息之遺傳,即建立在DNA「脫氧核糖核苷酸」(DeoxyriboNucleicAcid)之上。
DNA是生命體的遺傳物質,被稱為「基因」,大多數存在於細胞核的染色體中(部分在線粒體中),DNA中有四個鹼基(其名稱代表發現來源):腺嘌呤(A),鳥嘌呤(G),胞嘧啶(C)和胸腺嘧啶(T)。人類約有三十億個鹼基,這些鹼基排列順序,如同字母般組成文句,代表著身體的各種信息。
DNA鹼基分為兩對,腺嘌呤A、胸腺嘧啶T和胞嘧啶C、鳥嘌呤G,各基極還連接到一個糖分子和磷酸分子,合稱為核苷酸。核苷酸以雙螺旋式存在,鹼基對則像一個一個的階梯,垂直向兩側援升。當雙螺旋鏈分解為單鏈,是稱RNA(RiboNucleicAcid),即核糖核酸。核糖核酸能夠複製,並能還原成為脫氧核糖核酸。
去氧核糖核酸(DNA,以下簡稱雙核)是兩根核糖核酸(RNA,以下簡稱單核)絞合成雙軌、螺旋狀的梯形骨架,是正常的穩定狀態,遺傳訊息即貯存於此。單核則是不穩定的工作狀態,其階梯上排滿了前述的鹼基。由於鹼基陰陽相吸的作用力,必須與另一半組合成對,很不穩定。單核一旦找到了對象,成家立業,就成為安定的雙核。
基本遺傳單位為具有功能性的DNA序列,基因通過指導蛋白質的合成來表達自己所攜帶的遺傳信息,從而控制生物個體的性狀表現。人類約有兩萬至兩萬五千個基因。
任何系統有了基因,利用基因將系統發揚光大,遂有基因工程。生命體成之於自然,人類充其量只能將某些作物性質加以改造,使之增產或加入其他特性,是稱基因改造。本書名之為「漢字基因工程」係針對漢民族使用之文字,尋求其中的基因,以期達到溝通、應用最佳效果。
事實上,漢民族係中國56個民族之一,約佔總人口92%。漢族傳說是上古炎、黃二帝之後裔,數千年來,世代定居於中原華夏地域,沿襲了當地文化思想、習俗人情。漢字又稱象形字,發韌於6000年前(西安市東郊半坡村有象形文字遺物出土),後來衍變為甲骨文、大篆、金文、籀文、小篆、隸書、草書、楷書等,一脈相承,統稱為「漢字」。
漢字與拼音文字是兩種完全不同的系統,拼音文僅有近30個簡單的字母,可以拼出各種語音,廣為今世各人民使用。而漢字係象形文字,字形方整,一字一圖,且與發音無干,舉世僅漢人使用。
二十世紀,中國國力衰退,在西方列強的輪番侵襲下,政體幾難維持,而傳統文化更是面臨 亡。從宇宙進化立場來看,中國只是一個地域性的政體,但是歷經數千年的陶冶,中華文化曾給人類奠定了精神文明的曙光。問題在,時代日新月異,一種文化的存亡,端視其所代表的價值。準此,中華傳統文化的價值何在,正是吾人應該底瞭解的課題。
亡。從宇宙進化立場來看,中國只是一個地域性的政體,但是歷經數千年的陶冶,中華文化曾給人類奠定了精神文明的曙光。問題在,時代日新月異,一種文化的存亡,端視其所代表的價值。準此,中華傳統文化的價值何在,正是吾人應該底瞭解的課題。
欲問漢文化的價值,首應瞭解漢字的存續,漢字的存續涉及一個深層次問題:漢文化係進化史上偶發或必然的現象。若是偶發,遲早將煙消雲散;因為必然的現象必有必然的因果,這才是炎黃子孫值得追究的課題。「倉頡系統」成功後,作者分析其中因果,竟然發現漢字概念一如生命基因,在混沌一片中,曙光乍現!茲一一敘述如下:
第一節 基因結構
無盡宇宙奠基於精簡的要素,物質無窮,卻只有百餘元素;元素又源自更精簡的分子、原子。生命看似複雜難解,待遺傳基因真相大白,才發現宇宙之奧妙,基因竟係兩種要素合成,一為結構、一為基因。
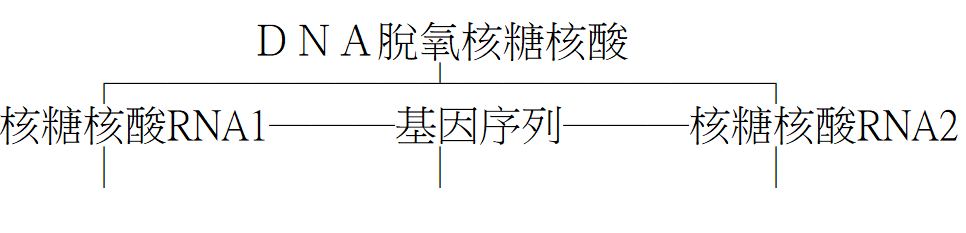
結構:DNA脫氧核糖核酸又稱「雙核」,是兩個「單核」、RNA核糖核酸絞合而成。在雙核的兩核之間,係由無數成對的「核鹼基Nucleobase」跨接,是稱「基因序列」,圖示如下:
結構圖
基因:四個鹼基分成兩對,其中A與T是一對,C與G是另一對,兩對又合成鹼基對,可以控制蛋白質的成長,是為「基因」。基因只有AT、TA,或CG、GC兩兩成對的排列組合,但各對之間組合無限。這種排列能吸引相對的鹼基組合之,如在單核的梯級上有A鹼基,則可吸引一個T鹼基;同理,如單核上有T則會吸引A(C吸引G,G吸引C)。
這種機制能將雙核分子「氧化」,成為單核分子。單核分子上的鹼基找到另一半對象後,又還原成為「去氧」的雙核分子,這樣一段一段的分解、還原,便成為生物的複製。生物體在這種複製的序列過程中,根據雙核分子上鹼基的排列組合,能將長時期演化所得的訊息,一代一代遺傳下去。
基因圖

基因是客觀物質,但是由單核到雙核之複製、及雙核到單核的解除,則是各鹼基自主的變化,換句話說,基因複製是「主觀精神行為」。由於基因之行為早在鹼基分子形成之前已經確定,C吸引G,G吸引C取決於分子結構,其複製依賴客觀環境,所以其「自主性變化」必然又受到客觀制約,成為主客一體的生命特性。
如果僅有四種鹼基,能代表的訊息顯然有限,以人類為例,基因由23對染色體組成,其中一條X染色體和一條Y染色體,基因組則含有約30億個鹼基對,代表了人生一切變化。實際上,宇宙的本象便是「以簡馭繁」,如同易經的分類,兩儀分成四象,四象分成八卦,上下卦再相合,成為六十四卦。由六十四卦排列組合,可以表達宇宙中一切的變化。
因此,再以漢字概念分類(詳見第二章、第三節)為例,作表如下:
再下去,是兩個核糖核酸的單鍵、合成脫核糖核酸雙鍵,藉著基因鹼基的排列組合,一連串的基因訊息,展開了生命體的點點滴滴。同理,在漢字上,將字首、字身組合成字,再以概念之抽象、具象與認識、行為組合成詞(象徵詞、觀念詞,詳見《詞易》),由詞組成文句(詳見《文易》)、由句成文,最後以文章代表意念。如此,基因序列與概念序列,同屬動態精神的指引藍圖,由微而著,宇宙、人生依序可解。
漢字係「漢民族文化文字」之統稱,除了文字本身係據象形所形成之概念外,尚有遵循自然之生活習俗,以及崇尚序列之倫理思想、抑己和眾之道德觀念在內。但由於漢字源自象形,一字一形,形音分離,與舉世各國所採用之拼音文字迥然有別。值今資訊時代,任何文字若無法與電腦相通,必然面臨淘汰滅絕的命運。
作者有鑑於此,利用「易理分類」,設計了供電腦輸入之「倉頡系統」,以「字碼、字序、字體、字形、字音、字義、字辨、字用」八大功能,一舉解決了漢字面臨的困境。
所謂的「易理分類」,與基因結構異曲同功。因此,隨著將倉頡輸入法的功能展開,各種功能下皆有不同的「基因」,分別代表不同的性能。
茲將易理分類之結構說明如下:
易理結構為《易經》之基本,但因古人缺乏具體之「系統觀」,本表係作者整理而得。
「結構定義」指《易傳》文字陳述之「易有太極,是生兩儀。兩儀生四象,四象生八卦。」太極相當於點,於系統中即為「漢字倉頡系統」;將各點連接,產生一維之線,線有兩端,是稱兩儀,於系統為「客觀、主觀」;兩儀為二維之面,面有四角,分別代表「抽象、具象、認認、應用」;再生為三維,成八卦之「字碼、字序、字形、字體、字音、字義、字辨、字用」。
以上倉頡系統,於客觀,有抽象體如「字碼、字序」,為求與拼音系統同步,係採用ASCII碼。具象指「字體、字形」,漢字字體甚多,有「篆、隸、草、行、楷」等,字形則隨字體一一有別。於主觀,有供認識之「字音、字義」,字音供語音辨識、字義供意識理解。另外有供應用之文字辨識「字辨」及供學習、寫作等「字用」之具體理論。
此外,倉頡系統之根據乃「漢字概念」,再將概念代入上表,遂得「漢字概念分類」,如:

根據上述「漢字基因分類」表,於結構之「一維線」,概念系統有「靜態、客觀」之體,又有「動態、主觀」之用,相當於「基因」之核糖核酸;當概念組合為觀念(詳見《詞易》),形成「脫氣核糖核酸」,漢文遂有了生命力。
於結構「二維面」,漢字也有四個「義基(相當於鹼基)」其中體(A)、用(T)是一對,因(C)、果(G)是另一對。在此,體用、用體之組合稱「象徵詞」,係概念符號、數字之代表;因果、果因則組合為「觀念詞」。
倉頡系統另定了字首、字身的結合規律,以供取碼用。漢字字首為單核如RNA、字身亦然,組合成字則如DNA之雙核,文字之基因「體、用、因、果」各各就位,悉如下表:

倉頡系統係因應時代需要,根據漢字之特性所設計者,計有八大功能,分別運用在八種不同的溝通環境上。此八大功能全屬漢字概念之體系,於不同之應用領域,其基因用法各異,特分別闡述如下:
一、字碼:
原則上力求保持漢字固有形狀,於取碼之餘,使用者能記憶字形、電腦得保存漢字象徵,重點在於文化的延續,並非求一時取碼快速,滿足市場需要者。
倉頡字母只有二十四個,在英文26個字母中,留出兩個供特殊發展用:x留供取碼困難時選用、z作連續字串定義之用。但因作者專心研究發展,無意市場,以致倉頡中文系統推廣失敗,使用者不多,應用者更少。
漢字分獨體與組合字,獨體可作字身;組合字由字首與字身之字碼合而成。各字皆有字碼組成漢字時,取「字首」及「字身」之碼合為一字。凡「獨體字」取一至四碼,「字首」取一至兩碼、「字身」取一至三碼;最多取五碼。
凡字首一碼已足是稱「單字首」,否則為「複字首」。
本項字碼即為「倉頡輸入法」,經台、港等地試用達三十餘年。由於早期放棄專利,推廣不易,致全部功能懸諸高閣。此字碼除供鍵盤輸入外,尚具有「字首、字身」之「理解基因」,應用於漢文自然語言,頗有成效(詳見「倉頡輸入法手冊」)。
倉頡字碼之基因結構如下:
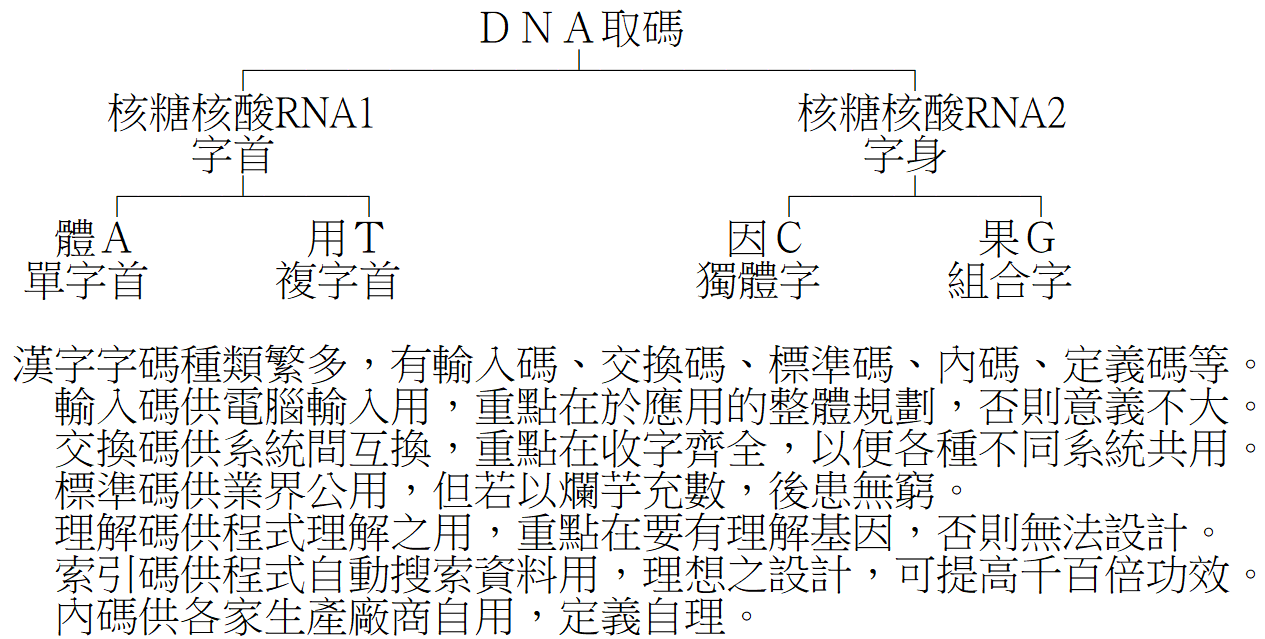
為了發揮最大效益,倉頡系統將「字碼」建立在倉頡輸入法上,同時可當作輸入碼、理解碼、內碼、索引碼使用。在大量資料處理時,若要尋找某一類型、或某一筆資料,「字碼」的良窳,其效率的差異有天淵之別。
「倉頡內碼」係將24個字母各取其中5位元,五碼共25位元,壓縮為四字元後,留出7位元供各種定用。
倉頡碼在設計時,已將字形、字義分類考慮進去,以致在資料索引時,可以作正反雙向比對(以碼查概念、及以概念查碼)。此內碼為三十二位元,其中前五個位元專供文字分類,倉頡輸入碼佔二十五位元,可容約千萬字;最後二位元保留給子字集分類用。
二、字序:
倉頡輸入法有二十四個「漢字字母」供文字排序。《漢字基因字典》及「漢文史資料庫」採本字序,證明應用效率與拼音字母相等。
字序乃索引基因,在資料大量使用時,由於漢字係方塊字形,每字四字元,整齊劃一,作為索引遠較不等長之英文有效。
非從事資料處理者,不瞭解文字索引的要性,甚至有些自以為是者,不知利用字碼的特性,為了增進處理效能,另行建立序列對照表,極不直觀。每當資料建檔、搜索時,都要經過兩道或三道手續,效率損失很大。
如果資料放置方式沒有直觀的順序,則完全沒有效率可言。
三、字體:
隨著環境的變遷,漢字字體因政體、書寫工具、應用方式而有所不同,傳統有:「甲骨文、金文、大篆、小篆、隸書、草書、行書、楷書」等,字形則神髓如故但筆形有別。
於客觀條件,甲骨文是刻劃在甲骨之上者,筆形銳直;金文則澆鑄於金屬器皿上者,形狀厚實;大、小篆已有毛筆寫具,字形古拙;隸書乃隸人工作所為,係用筆刷書寫;至草、行、楷毛筆盛行,故字形靈巧成熟。近代有印刷體如宋、仿宋、明、黑、圓及多種藝術體,各有特色及適應場合。

四、字形(筆形)。
基本向量筆形9個,字根64個,供字庫組字用(詳見「中文字庫介紹」)。
「漢字大字庫」係根據本字形基因,以200KB系統空間,採用無級次放大,每字之組成耗中央處理器系統脈衝約300個,可組成各種字形約數千萬個。
「字形」所衍生之字庫,可以徹底解決當前中文系統文字不足與不能兼容的困境。目前完成之第六代中文字形產生器,所佔程式空間僅160KB,若用倉頡碼則不需儲存任何內碼表,有碼即有字。每個字形皆可作各種大小及字體的變化,在速度上,以3Gz CPU每秒鐘可組成16*16之字形四萬六千個。
由於研究與商品性質不同,上述字形產生器並未推廣成為商品,記載於此係供有心人士參考,全部技術業已公佈,任憑取用。
五、字音:即語音。
六書中之「形聲」,適用於八成以上之漢字,可供語音辨識及合成用。
於語音辨識中,本系統採用「波形追蹤法」,可望做到不受環境干擾,能過濾噪音。尤其是此法於單音辨識之正確率極高,幾達百分之百;個人特徵亦可由波沿特徵,辨率八成;情緒緒亦同。程式空間約佔64KB,資料約佔20KB;辨識速度則受採音限制,若以技術論,以3Gz CPU每秒鐘可每秒可辨音一億個以上。
字音乃溝通基因,有母音及子音,母音由頻率決定性別、年齡,波形決定聲音感受;子音則由發聲部位因爆發、摩擦、送風、擠壓等產生之音形,及高低起伏長短頓挫之音相決定之。
其基因結構如下表:
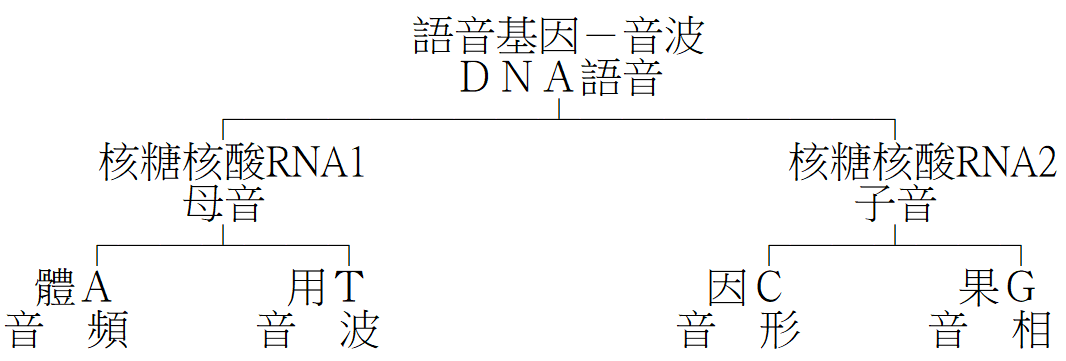
「字音」可供語音辨識及語音合成之用,任何一種漢字輸入法均須經過學習,推廣不易。
若用語音辨識輸入,效果最佳。同時,當理解系統完成後,再配以自然語言,語音的辨識與合成更是不可或缺的工具了。
語音辨識早年皆採數學模式,即以行列式之統計分辨之。近來多採音訊壓縮比對式,效果較佳。本法直接取聲音之基本因素,於結構取音波之振盪為母音,取聲音形相子音。
漢語母音有「阿A伊E哎I歐O悠U」五種,子音則有齒、唇、喉、舌、風聲等。各音皆可化為點陣視訊,再分析其波形即可(詳情見拙著《模擬真實》)。
六、字義:
漢字傳衍千年,約有八萬餘留存,其中,經考究過的錯別字幾佔兩成,不再使用之閑字約五成,餘字約近三萬。於此三萬字中,絕大多數為形聲字,形聲字緣自部首與字身之結合,部首定義、字身發音。凡歷代人仕、山川河流、地理方位、動物植物等皆須有名,其數無窮無盡、且累出常變,將形聲字視若符號,實用正宜。
象形字時代久遠,難以稽考,所幸常有甲骨出土,學者已整理出三千定義明確之字,與當今概念若合符節。此外,尚有五千非符號之形聲字,其部首、字身皆係象形,見象知源、溯源得義。作者歷數年時間,翻閱古藉,整理為字義基因。
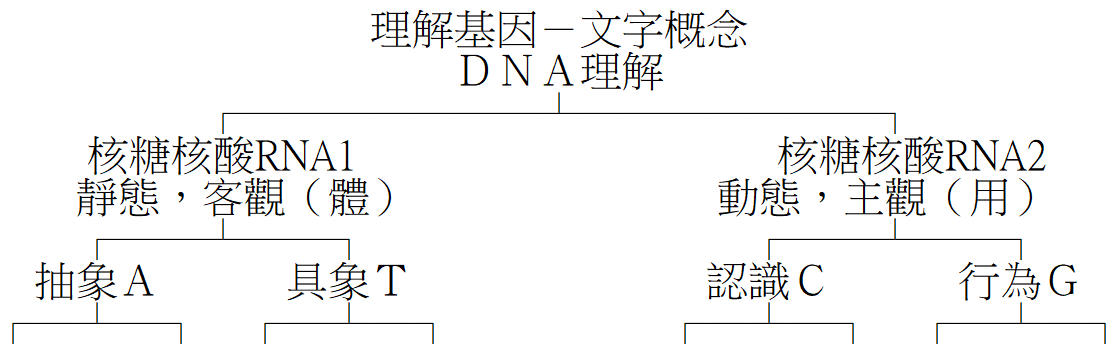
漢字基因各大功能中最重要的是「字義」基因,由於漢字的「象徵」特性,概念在大眾約定俗成的運作下,對一應客觀現象、事物以及主觀感受、認識等,都形成了合適的「字義基因」作為理解的介面。
於靜態,大自然中客觀之事體,相當於單核之一,其下有抽象之鹼基A,具象之鹼基T。
而於動態,人類主觀認識之鹼基C,與行為之鹼基G是為用。從理論上說,但凡某一機體,能於大自然中將各種事物正確無誤地應用於其主觀動作、行為,即稱理解。
同時,漢字來自象形,故而概念中亦具有圖形基因,抽象之鹼基,可先建立象徵資料庫,具象客觀體則直接建立圖形庫;至於認識與行為鹼基,則直接接以概念基因、再經理解系統轉化為動態圖形即可。
當然,科學重視實證,上述基因必須經過驗證,始能奠定其價值。為此,文化傳信公司特別設計了「全自動圖文系統」,以輸入漢字(或由記憶調出)的方式,即時在電腦、手機的屏幕上,直接顯示與輸入一致的動畫圖形。
表面看來,此事不可思議,其實,在字義基因與圖形基因同步下,文字、劇本原本就是客觀圖形的表徵。關鍵在於字義及圖形的基因,人有意識,意識能理解概念,概念能代表圖形,電腦系統能及時、正確地將各種基因聯繫為一,就是圖文一體的全自動系統。
七、字辨:
以掃瞄點陣資料輸入,利用「線性追蹤法」,比對前述七十三類字形基因特徵,轉換之字碼即為文字辨識。由於字形與字辨基因相同,完全符合人類認字(辨識)及寫字(組字)的根本原理。
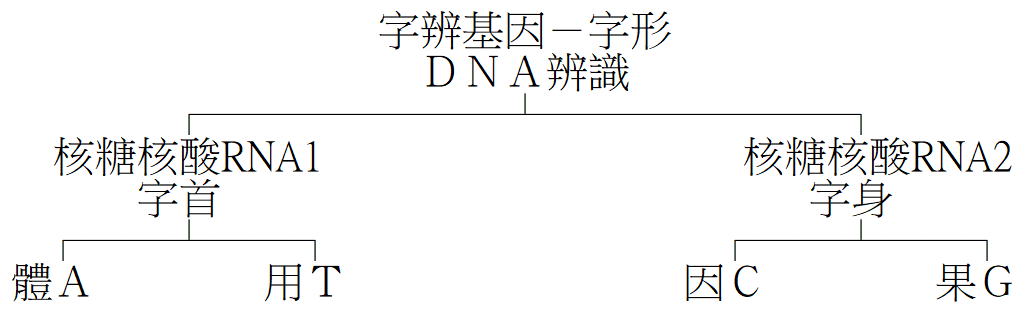
「字辨」有多種功能,除了文字辨識外,也有影像辨識的基因在內。只是限於中文平台的機能,「字辨」尚須配合其他硬體設施。
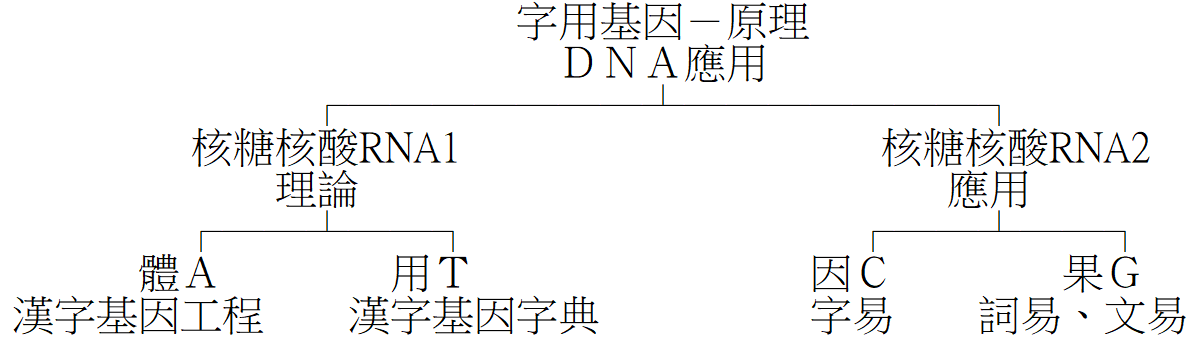
八、字用:概念應用
有《漢字基因工程、漢字基因字典》《字易、詞易、文易》供各界使用。
由於紙本污染環璄,以上五書僅在網上公佈,歡迎取用(網址:CNFLABS.COM 及開放文學.COM)
第一章 基因工程
本站之資料、著作歡迎網友註明出處後轉載,
第一章 基因工程
第一節 基因結構
第一章 基因工程基因Gene一詞原為希臘文,意思為「生」,指攜帶遺傳訊息的物質。於有性生殖時,性細胞經過染色體的減數分裂,再由陰陽兩性結合還原為一。新生命誕生後,不僅可保持兩代之間之相同性,且能形成逐代的演變進化。其生命訊息之遺傳,即建立在DNA「脫氧核糖核苷酸」(DeoxyriboNucleicAcid)之上。
DNA是生命體的遺傳物質,被稱為「基因」,大多數存在於細胞核的染色體中(部分在線粒體中),DNA中有四個鹼基(其名稱代表發現來源):腺嘌呤(A),鳥嘌呤(G),胞嘧啶(C)和胸腺嘧啶(T)。人類約有三十億個鹼基,這些鹼基排列順序,如同字母般組成文句,代表著身體的各種信息。
DNA鹼基分為兩對,腺嘌呤A、胸腺嘧啶T和胞嘧啶C、鳥嘌呤G,各基極還連接到一個糖分子和磷酸分子,合稱為核苷酸。核苷酸以雙螺旋式存在,鹼基對則像一個一個的階梯,垂直向兩側援升。當雙螺旋鏈分解為單鏈,是稱RNA(RiboNucleicAcid),即核糖核酸。核糖核酸能夠複製,並能還原成為脫氧核糖核酸。
去氧核糖核酸(DNA,以下簡稱雙核)是兩根核糖核酸(RNA,以下簡稱單核)絞合成雙軌、螺旋狀的梯形骨架,是正常的穩定狀態,遺傳訊息即貯存於此。單核則是不穩定的工作狀態,其階梯上排滿了前述的鹼基。由於鹼基陰陽相吸的作用力,必須與另一半組合成對,很不穩定。單核一旦找到了對象,成家立業,就成為安定的雙核。
基本遺傳單位為具有功能性的DNA序列,基因通過指導蛋白質的合成來表達自己所攜帶的遺傳信息,從而控制生物個體的性狀表現。人類約有兩萬至兩萬五千個基因。
任何系統有了基因,利用基因將系統發揚光大,遂有基因工程。生命體成之於自然,人類充其量只能將某些作物性質加以改造,使之增產或加入其他特性,是稱基因改造。本書名之為「漢字基因工程」係針對漢民族使用之文字,尋求其中的基因,以期達到溝通、應用最佳效果。
事實上,漢民族係中國56個民族之一,約佔總人口92%。漢族傳說是上古炎、黃二帝之後裔,數千年來,世代定居於中原華夏地域,沿襲了當地文化思想、習俗人情。漢字又稱象形字,發韌於6000年前(西安市東郊半坡村有象形文字遺物出土),後來衍變為甲骨文、大篆、金文、籀文、小篆、隸書、草書、楷書等,一脈相承,統稱為「漢字」。
漢字與拼音文字是兩種完全不同的系統,拼音文僅有近30個簡單的字母,可以拼出各種語音,廣為今世各人民使用。而漢字係象形文字,字形方整,一字一圖,且與發音無干,舉世僅漢人使用。
二十世紀,中國國力衰退,在西方列強的輪番侵襲下,政體幾難維持,而傳統文化更是面臨
亡。從宇宙進化立場來看,中國只是一個地域性的政體,但是歷經數千年的陶冶,中華文化曾給人類奠定了精神文明的曙光。問題在,時代日新月異,一種文化的存亡,端視其所代表的價值。準此,中華傳統文化的價值何在,正是吾人應該底瞭解的課題。欲問漢文化的價值,首應瞭解漢字的存續,漢字的存續涉及一個深層次問題:漢文化係進化史上偶發或必然的現象。若是偶發,遲早將煙消雲散;因為必然的現象必有必然的因果,這才是炎黃子孫值得追究的課題。「倉頡系統」成功後,作者分析其中因果,竟然發現漢字概念一如生命基因,在混沌一片中,曙光乍現!茲一一敘述如下:
第一節 基因結構
無盡宇宙奠基於精簡的要素,物質無窮,卻只有百餘元素;元素又源自更精簡的分子、原子。生命看似複雜難解,待遺傳基因真相大白,才發現宇宙之奧妙,基因竟係兩種要素合成,一為結構、一為基因。
結構:DNA脫氧核糖核酸又稱「雙核」,是兩個「單核」、RNA核糖核酸絞合而成。在雙核的兩核之間,係由無數成對的「核鹼基Nucleobase」跨接,是稱「基因序列」,圖示如下:
結構圖
基因:四個鹼基分成兩對,其中A與T是一對,C與G是另一對,兩對又合成鹼基對,可以控制蛋白質的成長,是為「基因」。基因只有AT、TA,或CG、GC兩兩成對的排列組合,但各對之間組合無限。這種排列能吸引相對的鹼基組合之,如在單核的梯級上有A鹼基,則可吸引一個T鹼基;同理,如單核上有T則會吸引A(C吸引G,G吸引C)。
這種機制能將雙核分子「氧化」,成為單核分子。單核分子上的鹼基找到另一半對象後,又還原成為「去氧」的雙核分子,這樣一段一段的分解、還原,便成為生物的複製。生物體在這種複製的序列過程中,根據雙核分子上鹼基的排列組合,能將長時期演化所得的訊息,一代一代遺傳下去。
基因圖
基因是客觀物質,但是由單核到雙核之複製、及雙核到單核的解除,則是各鹼基自主的變化,換句話說,基因複製是「主觀精神行為」。由於基因之行為早在鹼基分子形成之前已經確定,C吸引G,G吸引C取決於分子結構,其複製依賴客觀環境,所以其「自主性變化」必然又受到客觀制約,成為主客一體的生命特性。
如果僅有四種鹼基,能代表的訊息顯然有限,以人類為例,基因由23對染色體組成,其中一條X染色體和一條Y染色體,基因組則含有約30億個鹼基對,代表了人生一切變化。實際上,宇宙的本象便是「以簡馭繁」,如同易經的分類,兩儀分成四象,四象分成八卦,上下卦再相合,成為六十四卦。由六十四卦排列組合,可以表達宇宙中一切的變化。
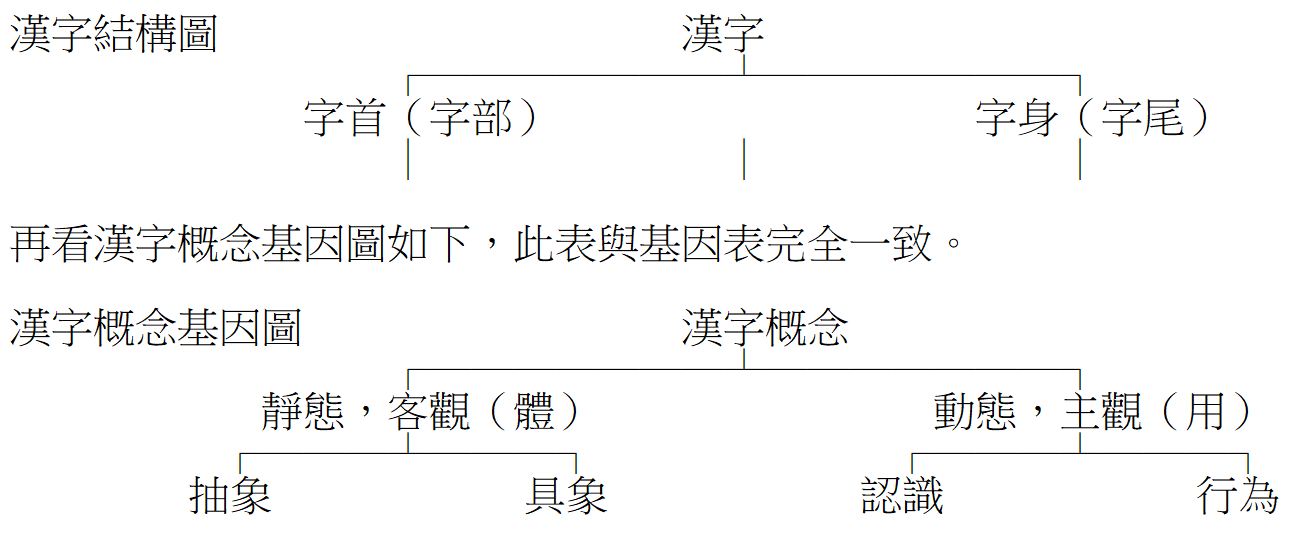
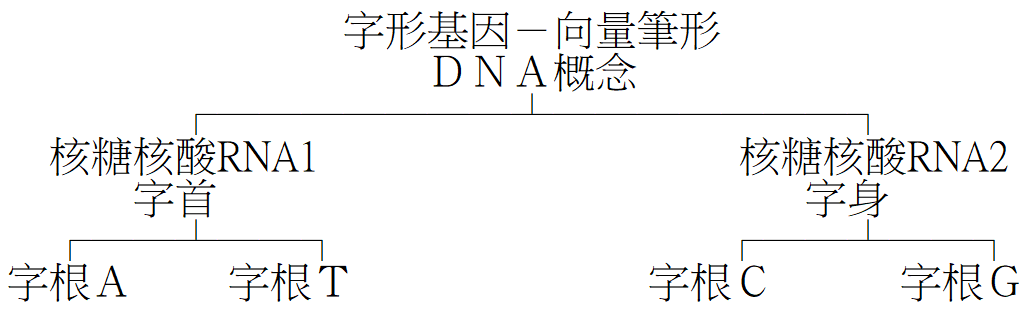
因此,再以漢字概念分類(詳見第二章、第三節)為例,作表如下:
再下去,是兩個核糖核酸的單鍵、合成脫核糖核酸雙鍵,藉著基因鹼基的排列組合,一連串的基因訊息,展開了生命體的點點滴滴。同理,在漢字上,將字首、字身組合成字,再以概念之抽象、具象與認識、行為組合成詞(象徵詞、觀念詞,詳見《詞易》),由詞組成文句(詳見《文易》)、由句成文,最後以文章代表意念。如此,基因序列與概念序列,同屬動態精神的指引藍圖,由微而著,宇宙、人生依序可解。
漢字係「漢民族文化文字」之統稱,除了文字本身係據象形所形成之概念外,尚有遵循自然之生活習俗,以及崇尚序列之倫理思想、抑己和眾之道德觀念在內。但由於漢字源自象形,一字一形,形音分離,與舉世各國所採用之拼音文字迥然有別。值今資訊時代,任何文字若無法與電腦相通,必然面臨淘汰滅絕的命運。
作者有鑑於此,利用「易理分類」,設計了供電腦輸入之「倉頡系統」,以「字碼、字序、字體、字形、字音、字義、字辨、字用」八大功能,一舉解決了漢字面臨的困境。
所謂的「易理分類」,與基因結構異曲同功。因此,隨著將倉頡輸入法的功能展開,各種功能下皆有不同的「基因」,分別代表不同的性能。
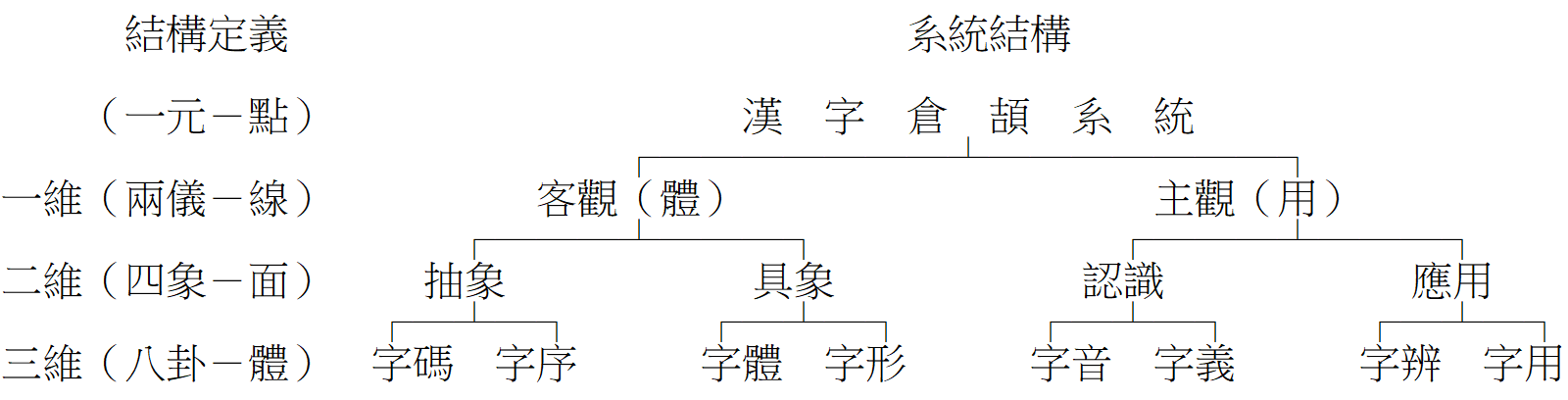
茲將易理分類之結構說明如下:
易理結構為《易經》之基本,但因古人缺乏具體之「系統觀」,本表係作者整理而得。
「結構定義」指《易傳》文字陳述之「易有太極,是生兩儀。兩儀生四象,四象生八卦。」太極相當於點,於系統中即為「漢字倉頡系統」;將各點連接,產生一維之線,線有兩端,是稱兩儀,於系統為「客觀、主觀」;兩儀為二維之面,面有四角,分別代表「抽象、具象、認認、應用」;再生為三維,成八卦之「字碼、字序、字形、字體、字音、字義、字辨、字用」。
以上倉頡系統,於客觀,有抽象體如「字碼、字序」,為求與拼音系統同步,係採用ASCII碼。具象指「字體、字形」,漢字字體甚多,有「篆、隸、草、行、楷」等,字形則隨字體一一有別。於主觀,有供認識之「字音、字義」,字音供語音辨識、字義供意識理解。另外有供應用之文字辨識「字辨」及供學習、寫作等「字用」之具體理論。
此外,倉頡系統之根據乃「漢字概念」,再將概念代入上表,遂得「漢字概念分類」,如:
根據上述「漢字基因分類」表,於結構之「一維線」,概念系統有「靜態、客觀」之體,又有「動態、主觀」之用,相當於「基因」之核糖核酸;當概念組合為觀念(詳見《詞易》),形成「脫氣核糖核酸」,漢文遂有了生命力。
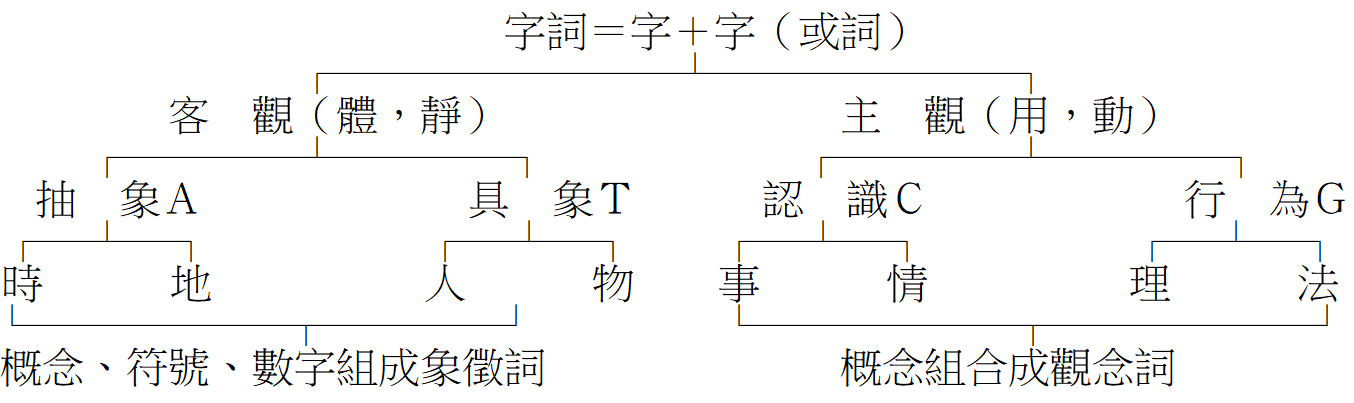
於結構「二維面」,漢字也有四個「義基(相當於鹼基)」其中體(A)、用(T)是一對,因(C)、果(G)是另一對。在此,體用、用體之組合稱「象徵詞」,係概念符號、數字之代表;因果、果因則組合為「觀念詞」。
倉頡系統另定了字首、字身的結合規律,以供取碼用。漢字字首為單核如RNA、字身亦然,組合成字則如DNA之雙核,文字之基因「體、用、因、果」各各就位,悉如下表:
倉頡系統係因應時代需要,根據漢字之特性所設計者,計有八大功能,分別運用在八種不同的溝通環境上。此八大功能全屬漢字概念之體系,於不同之應用領域,其基因用法各異,特分別闡述如下:
一、字碼:
原則上力求保持漢字固有形狀,於取碼之餘,使用者能記憶字形、電腦得保存漢字象徵,重點在於文化的延續,並非求一時取碼快速,滿足市場需要者。
倉頡字母只有二十四個,在英文26個字母中,留出兩個供特殊發展用:x留供取碼困難時選用、z作連續字串定義之用。但因作者專心研究發展,無意市場,以致倉頡中文系統推廣失敗,使用者不多,應用者更少。
漢字分獨體與組合字,獨體可作字身;組合字由字首與字身之字碼合而成。各字皆有字碼組成漢字時,取「字首」及「字身」之碼合為一字。凡「獨體字」取一至四碼,「字首」取一至兩碼、「字身」取一至三碼;最多取五碼。
凡字首一碼已足是稱「單字首」,否則為「複字首」。
本項字碼即為「倉頡輸入法」,經台、港等地試用達三十餘年。由於早期放棄專利,推廣不易,致全部功能懸諸高閣。此字碼除供鍵盤輸入外,尚具有「字首、字身」之「理解基因」,應用於漢文自然語言,頗有成效(詳見「倉頡輸入法手冊」)。
倉頡字碼之基因結構如下:
為了發揮最大效益,倉頡系統將「字碼」建立在倉頡輸入法上,同時可當作輸入碼、理解碼、內碼、索引碼使用。在大量資料處理時,若要尋找某一類型、或某一筆資料,「字碼」的良窳,其效率的差異有天淵之別。
「倉頡內碼」係將24個字母各取其中5位元,五碼共25位元,壓縮為四字元後,留出7位元供各種定用。
倉頡碼在設計時,已將字形、字義分類考慮進去,以致在資料索引時,可以作正反雙向比對(以碼查概念、及以概念查碼)。此內碼為三十二位元,其中前五個位元專供文字分類,倉頡輸入碼佔二十五位元,可容約千萬字;最後二位元保留給子字集分類用。
二、字序:
倉頡輸入法有二十四個「漢字字母」供文字排序。《漢字基因字典》及「漢文史資料庫」採本字序,證明應用效率與拼音字母相等。
字序乃索引基因,在資料大量使用時,由於漢字係方塊字形,每字四字元,整齊劃一,作為索引遠較不等長之英文有效。
非從事資料處理者,不瞭解文字索引的要性,甚至有些自以為是者,不知利用字碼的特性,為了增進處理效能,另行建立序列對照表,極不直觀。每當資料建檔、搜索時,都要經過兩道或三道手續,效率損失很大。
如果資料放置方式沒有直觀的順序,則完全沒有效率可言。
三、字體:
隨著環境的變遷,漢字字體因政體、書寫工具、應用方式而有所不同,傳統有:「甲骨文、金文、大篆、小篆、隸書、草書、行書、楷書」等,字形則神髓如故但筆形有別。
於客觀條件,甲骨文是刻劃在甲骨之上者,筆形銳直;金文則澆鑄於金屬器皿上者,形狀厚實;大、小篆已有毛筆寫具,字形古拙;隸書乃隸人工作所為,係用筆刷書寫;至草、行、楷毛筆盛行,故字形靈巧成熟。近代有印刷體如宋、仿宋、明、黑、圓及多種藝術體,各有特色及適應場合。
四、字形(筆形)。
基本向量筆形9個,字根64個,供字庫組字用(詳見「中文字庫介紹」)。
「漢字大字庫」係根據本字形基因,以200KB系統空間,採用無級次放大,每字之組成耗中央處理器系統脈衝約300個,可組成各種字形約數千萬個。
「字形」所衍生之字庫,可以徹底解決當前中文系統文字不足與不能兼容的困境。目前完成之第六代中文字形產生器,所佔程式空間僅160KB,若用倉頡碼則不需儲存任何內碼表,有碼即有字。每個字形皆可作各種大小及字體的變化,在速度上,以3Gz CPU每秒鐘可組成16*16之字形四萬六千個。
由於研究與商品性質不同,上述字形產生器並未推廣成為商品,記載於此係供有心人士參考,全部技術業已公佈,任憑取用。
五、字音:即語音。
六書中之「形聲」,適用於八成以上之漢字,可供語音辨識及合成用。
於語音辨識中,本系統採用「波形追蹤法」,可望做到不受環境干擾,能過濾噪音。尤其是此法於單音辨識之正確率極高,幾達百分之百;個人特徵亦可由波沿特徵,辨率八成;情緒緒亦同。程式空間約佔64KB,資料約佔20KB;辨識速度則受採音限制,若以技術論,以3Gz CPU每秒鐘可每秒可辨音一億個以上。
字音乃溝通基因,有母音及子音,母音由頻率決定性別、年齡,波形決定聲音感受;子音則由發聲部位因爆發、摩擦、送風、擠壓等產生之音形,及高低起伏長短頓挫之音相決定之。
其基因結構如下表:
「字音」可供語音辨識及語音合成之用,任何一種漢字輸入法均須經過學習,推廣不易。
若用語音辨識輸入,效果最佳。同時,當理解系統完成後,再配以自然語言,語音的辨識與合成更是不可或缺的工具了。
語音辨識早年皆採數學模式,即以行列式之統計分辨之。近來多採音訊壓縮比對式,效果較佳。本法直接取聲音之基本因素,於結構取音波之振盪為母音,取聲音形相子音。
漢語母音有「阿A伊E哎I歐O悠U」五種,子音則有齒、唇、喉、舌、風聲等。各音皆可化為點陣視訊,再分析其波形即可(詳情見拙著《模擬真實》)。
六、字義:
漢字傳衍千年,約有八萬餘留存,其中,經考究過的錯別字幾佔兩成,不再使用之閑字約五成,餘字約近三萬。於此三萬字中,絕大多數為形聲字,形聲字緣自部首與字身之結合,部首定義、字身發音。凡歷代人仕、山川河流、地理方位、動物植物等皆須有名,其數無窮無盡、且累出常變,將形聲字視若符號,實用正宜。
象形字時代久遠,難以稽考,所幸常有甲骨出土,學者已整理出三千定義明確之字,與當今概念若合符節。此外,尚有五千非符號之形聲字,其部首、字身皆係象形,見象知源、溯源得義。作者歷數年時間,翻閱古藉,整理為字義基因。
漢字基因各大功能中最重要的是「字義」基因,由於漢字的「象徵」特性,概念在大眾約定俗成的運作下,對一應客觀現象、事物以及主觀感受、認識等,都形成了合適的「字義基因」作為理解的介面。
於靜態,大自然中客觀之事體,相當於單核之一,其下有抽象之鹼基A,具象之鹼基T。
而於動態,人類主觀認識之鹼基C,與行為之鹼基G是為用。從理論上說,但凡某一機體,能於大自然中將各種事物正確無誤地應用於其主觀動作、行為,即稱理解。
同時,漢字來自象形,故而概念中亦具有圖形基因,抽象之鹼基,可先建立象徵資料庫,具象客觀體則直接建立圖形庫;至於認識與行為鹼基,則直接接以概念基因、再經理解系統轉化為動態圖形即可。
當然,科學重視實證,上述基因必須經過驗證,始能奠定其價值。為此,文化傳信公司特別設計了「全自動圖文系統」,以輸入漢字(或由記憶調出)的方式,即時在電腦、手機的屏幕上,直接顯示與輸入一致的動畫圖形。
表面看來,此事不可思議,其實,在字義基因與圖形基因同步下,文字、劇本原本就是客觀圖形的表徵。關鍵在於字義及圖形的基因,人有意識,意識能理解概念,概念能代表圖形,電腦系統能及時、正確地將各種基因聯繫為一,就是圖文一體的全自動系統。
七、字辨:
以掃瞄點陣資料輸入,利用「線性追蹤法」,比對前述七十三類字形基因特徵,轉換之字碼即為文字辨識。由於字形與字辨基因相同,完全符合人類認字(辨識)及寫字(組字)的根本原理。
「字辨」有多種功能,除了文字辨識外,也有影像辨識的基因在內。只是限於中文平台的機能,「字辨」尚須配合其他硬體設施。
八、字用:概念應用
有《漢字基因工程、漢字基因字典》《字易、詞易、文易》供各界使用。
由於紙本污染環璄,以上五書僅在網上公佈,歡迎取用(網址:CNFLABS.COM 及開放文學.COM)