轉简體
復原
關鍵問題之一,在於不論通訊技術再進步,網絡永遠不敷使用。這個道理正如當今的交通瓶頸一般。只要想想,如果每個人都擁有一部汽車,這個世界會變成什麼樣子?
每人一部汽車或許並無必要,更不可能眾人同時把車開到公路上。可是,基於人性的需求,任何人在任一時刻、任何地方,都有極高的欲望要與他人溝通。
在通訊工具尚無法滿足人類所有感官需求之前,人還無法想像出那種遠景。一旦雙向溝通能與虛擬實境結合,也就是説,人可以將其感官無限伸展到任何時空。到那時連外出旅行都可以免了,人安居斗室,只要把感官送出去,就是百億光年的外太空,也都能一一呈現眼前。
到了那一天,大部分人的生活,必然都擁塞在網絡上,整個宇宙也將聯成一氣。於是麻煩來了,究竟要有多少網絡頻道,才能滿足這無盡的需求?
不錯,硬體技術不斷進步,但是如果人人上網絡,且先不談雙向溝通,僅僅這傳達神經脈衝的網絡,除非每個人身上綁一根,否則不論怎樣都難以應付。
再説,當談到網絡時,有一個數據不能不顧,就是網絡上有多少個收發單位?在收發單位之間,又有多少通道?
目前在有線通訊上,除了電話線外,最進步的應屬光纖,其容載量是電話線的千餘倍,且正隨著技術的改進而增加。此外還有各種無線網絡,有局部性的,地域性的,也有衛星收發的,不一而足。
在網絡上,又是些什麼呢?最初當然只是類比式的訊號,現在有了二進位的技術,效率提高了,因為二進位訊號可以壓縮,而壓縮的倍數正是效率增進的比值。
由於訊號的性質不同,沒有人能明確地用數據説明,究竟類比訊號與二進位壓縮訊號的差值有多少。但在實際應用上,大家都承認至少有百倍以上的效益。只是有一個例外,那就是文字!基於這種符號的特性,可以將之設計成簡單的代碼!
代碼意為效率最高的組合,即令同樣利用二進位壓縮訊息,每一字形在視覺訊息上,如果使用代碼,在可以辨識的範圍內,以英文為例,最少可以節省六倍(中文為十六倍),多則難以估算。再若是語音,僅以每秒四個音節計(英文一個音節平均約五個字符,漢語僅為一個),目前一個音節在中等水準的壓縮信息下,較代碼約大上一千倍。換句話説,如果用代碼代替語音,網絡的功效至少可以增進一千倍。
真要把代碼用在網絡上,那就不僅僅是符號及語音的問題而已了,圖形所能節省的效率更高,功效也更大。比如説,影像通訊是當前最需要的功能,由於每秒鐘需要傳輸的動態信息太多,工程師們想盡辦法,比如把靜止且重複的影像保留,僅傳送有變化的部分。就這樣,該信息量還是大得驚人,幾十個人同時上線,就會造成交通堵塞!
能將圖形也編成代碼嗎?這正是當今全世界最高的高科技,且稱為「萬象編碼」。
顧名思義,萬象編碼是要將人能認知的所有信息,全部編成代碼。有哪些信息呢?
甲、文字
本人在二十年前,為中文電腦編了「倉頡碼」。實際上,當時我已有萬象編碼的想法,漢字編碼只是起步。一九七九年我曾在三軍大學演講,題目是「無線電話與中文通訊」,當時我即認為,有一天所有通訊都會利用編碼方式傳輸。到目前為止,至少,文字通訊已經採用代碼了,新的革命尚有待新的努力。
乙、語音
把全世界的語音統統加起來,單音不會超過兩千種。問題在語音中所夾帶的情感(語調)及音色(腔調),就人的溝通來説,也都屬於信息辨識的一部分。
因此,在為語音編碼時應詳細考慮清楚,以便未來在通訊時,能藉代碼的傳輸提升效率,而以辨識及合成技術自動編碼及還原。
語音的元素有五:音頻、音量、音形、音色、音速。
一、音頻:人耳所聞,約在60至3000週/秒之間,一般説來,男音在60至300週/秒之間,女音在150至500週/秒之間。此外還有四聲變化(以普通話為例),是以其起音到收音之間,第一聲頻率不變,第二聲起音降百分之十,收音升,第三聲起音降百分之二十,收音升,第四聲收音下降。
二、音量:音量主在偵測情緒,音量大時旨在提醒對方注意,音量小則為掩飾自己的主旨或避免打擾第三者。重音所在則為個人的性向及目的。
三、音形:分子音及母音兩類,母音為主,子音為輔。母音長而循環,子音短而止於分別處。兹以英文拼音字母為例,一一説明如下:
a-母音,發“啊”音,口大張,喉管音,四到五組波形。
b-子音,發“白”音,唇爆音。
c-子音,發“塞”音,氣摩音。
d-子音,發“得”音,舌爆音。
e-母音,發“呃”音,口張舌收,喉管音,三到四組波形加顫波。
f-子音,發“弗”音,唇摩音,中頻風聲。
g-子音,發“哥”音,喉爆音。
h-子音,發“黑”音,喉風聲。
i-母音,發“衣”音,口收舌收,喉震音,二到三組波形加顫波。
k-子音,發“克”音,喉爆音加風聲。
l-子音,發“兒”音,捲舌收無鼻音。
m-子音,發“姆”音,全鼻音。
n-子音,發“嗯”音,收鼻音。
o-母音,發“歐”音,口張,喉管音,三到四組波形。
p-子音,發“皮”音,唇爆音加風聲。
r-子音,發“兒”音,捲舌。
s-子音,發“尸”音,高頻風聲。
t-子音,發“提”音,舌爆音加風聲。
u-母音,發“烏”音,口微張,喉管音,二到三組波形。
四、音色:音沿振盪、音波比例、音形特徵、子音比重等,皆可用來辨識個人之音色變化。加以適當的編碼,即可作為個體辨識。
五、音速:漢語正常發音約每秒鐘四音,舉凡音與音之間的空隙,母音的週期等,都是輔助辨識的重要依據。
語音除了辨識外,尚可合成,其法適為辨識之反向。
丙、形像
形像雖然是無窮無盡,但在系統分類下,倒也沒有多少類別。舉凡視線所及,不外乎光的明暗(光源編碼),環境範圍(分類編碼),主觀立場(透視編碼),物體邊緣(曲線編碼),體用因果(機能編碼)等。此外,再根據應用時的需求,作重點綜合處理,就能逐步化繁為簡,最後以簡馭繁了。
由編碼到合成,是一體的兩面。最理想的編碼方式,則是與漢字基因的理論結合,以字義理解作為形像的定義準則(下文解説中,將編碼與合成視為一體,不再分別解釋)。
一、三維影像
三維影像是根據任意系統之三維座標設計的,計有XYZ之座標值、顔色或材質貼圖、結構體之聯接關係、物質物性定義以及燈光環境的參數等。
根據XYZ座標值,可以畫出物體表面的標準網線,再加上主觀之鏡頭位置,即可得一虛擬的透視模型。
顔色及材質決定於視訊要求,例如模擬真實與卡通兩者效果相去甚遠,卡通只是一種簡易的表達方法,資料內容不變,然無法表現材質。
結構體在作部位運動時,需要根據其聯結關係,設定轉動軸點、方向、角度、限性、重心、摩擦等,由程式控制摹擬出接近真實的運動。
物質物性定義供碰撞、接觸、摩擦以及各種真實環境下的運動如飄動、浮動、移動、游動、滾動等計算之用。
燈光環境參數等提供戲劇效果或傳真效應,如燈光代表了室內或室外的氣氛條件,只要確定光源及光效,就可以節省大量的圖形處理手續。
二、形像編碼
形像編碼是視覺辨識的基本課題,只要將視覺基因設定為辨識參數,再以層次分類為輔,就能得到有效的形像編碼。
層次分類可參考概念分類(詳見《漢字基因》),兹以「電腦」一詞為例,説明如下:
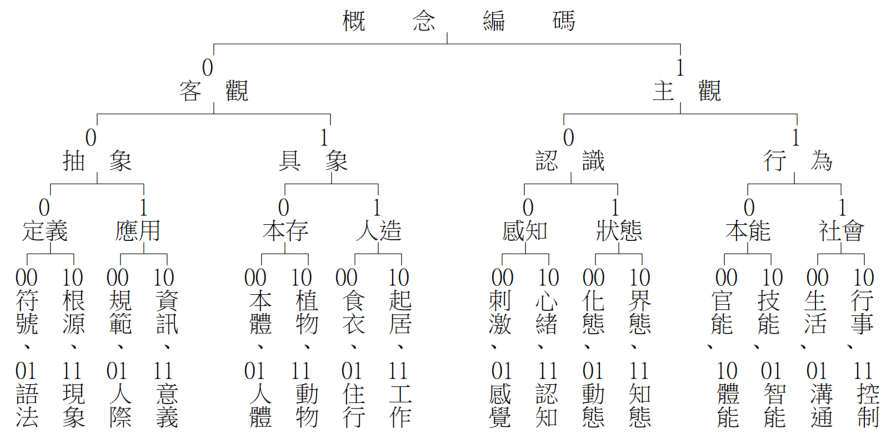
上述編碼表僅分至三十二類,其類每類之下尚有八種,如11工作類下有:
000文具 001樂器 010工具 011農具 100武器 101機器 110材料 111廢料

物體經辨識後得到編碼,代碼可供貯存及傳輸。應用時再以三維繪圖,根據資料庫將編碼還原繪為圖形。這種工作可利用硬體處理,只要速度快,擬真度高,就有實用價值。以傳輸語言為例,人講話時,每秒鐘平均發出五個音節,祇需十個字元而已。
若用音潻傳送,至少需8k字元,再談圖形,其數量更難以估計。
本站之資料、著作歡迎網友註明出處後轉載,
第五節 雙向溝通
人在溝通過程中,必須親自介入,才能獲得主動權。由於電腦及網絡的進步,這種參與性的雙向甚至多向同時溝通,已經成為事實。不過目前尚局限在通訊、會議等現場溝通階段。在戲劇上,尚有多項難題有待解決。關鍵問題之一,在於不論通訊技術再進步,網絡永遠不敷使用。這個道理正如當今的交通瓶頸一般。只要想想,如果每個人都擁有一部汽車,這個世界會變成什麼樣子?
每人一部汽車或許並無必要,更不可能眾人同時把車開到公路上。可是,基於人性的需求,任何人在任一時刻、任何地方,都有極高的欲望要與他人溝通。
在通訊工具尚無法滿足人類所有感官需求之前,人還無法想像出那種遠景。一旦雙向溝通能與虛擬實境結合,也就是説,人可以將其感官無限伸展到任何時空。到那時連外出旅行都可以免了,人安居斗室,只要把感官送出去,就是百億光年的外太空,也都能一一呈現眼前。
到了那一天,大部分人的生活,必然都擁塞在網絡上,整個宇宙也將聯成一氣。於是麻煩來了,究竟要有多少網絡頻道,才能滿足這無盡的需求?
不錯,硬體技術不斷進步,但是如果人人上網絡,且先不談雙向溝通,僅僅這傳達神經脈衝的網絡,除非每個人身上綁一根,否則不論怎樣都難以應付。
再説,當談到網絡時,有一個數據不能不顧,就是網絡上有多少個收發單位?在收發單位之間,又有多少通道?
目前在有線通訊上,除了電話線外,最進步的應屬光纖,其容載量是電話線的千餘倍,且正隨著技術的改進而增加。此外還有各種無線網絡,有局部性的,地域性的,也有衛星收發的,不一而足。
在網絡上,又是些什麼呢?最初當然只是類比式的訊號,現在有了二進位的技術,效率提高了,因為二進位訊號可以壓縮,而壓縮的倍數正是效率增進的比值。
由於訊號的性質不同,沒有人能明確地用數據説明,究竟類比訊號與二進位壓縮訊號的差值有多少。但在實際應用上,大家都承認至少有百倍以上的效益。只是有一個例外,那就是文字!基於這種符號的特性,可以將之設計成簡單的代碼!
代碼意為效率最高的組合,即令同樣利用二進位壓縮訊息,每一字形在視覺訊息上,如果使用代碼,在可以辨識的範圍內,以英文為例,最少可以節省六倍(中文為十六倍),多則難以估算。再若是語音,僅以每秒四個音節計(英文一個音節平均約五個字符,漢語僅為一個),目前一個音節在中等水準的壓縮信息下,較代碼約大上一千倍。換句話説,如果用代碼代替語音,網絡的功效至少可以增進一千倍。
真要把代碼用在網絡上,那就不僅僅是符號及語音的問題而已了,圖形所能節省的效率更高,功效也更大。比如説,影像通訊是當前最需要的功能,由於每秒鐘需要傳輸的動態信息太多,工程師們想盡辦法,比如把靜止且重複的影像保留,僅傳送有變化的部分。就這樣,該信息量還是大得驚人,幾十個人同時上線,就會造成交通堵塞!
能將圖形也編成代碼嗎?這正是當今全世界最高的高科技,且稱為「萬象編碼」。
顧名思義,萬象編碼是要將人能認知的所有信息,全部編成代碼。有哪些信息呢?
甲、文字
本人在二十年前,為中文電腦編了「倉頡碼」。實際上,當時我已有萬象編碼的想法,漢字編碼只是起步。一九七九年我曾在三軍大學演講,題目是「無線電話與中文通訊」,當時我即認為,有一天所有通訊都會利用編碼方式傳輸。到目前為止,至少,文字通訊已經採用代碼了,新的革命尚有待新的努力。
乙、語音
把全世界的語音統統加起來,單音不會超過兩千種。問題在語音中所夾帶的情感(語調)及音色(腔調),就人的溝通來説,也都屬於信息辨識的一部分。
因此,在為語音編碼時應詳細考慮清楚,以便未來在通訊時,能藉代碼的傳輸提升效率,而以辨識及合成技術自動編碼及還原。
語音的元素有五:音頻、音量、音形、音色、音速。
一、音頻:人耳所聞,約在60至3000週/秒之間,一般説來,男音在60至300週/秒之間,女音在150至500週/秒之間。此外還有四聲變化(以普通話為例),是以其起音到收音之間,第一聲頻率不變,第二聲起音降百分之十,收音升,第三聲起音降百分之二十,收音升,第四聲收音下降。
二、音量:音量主在偵測情緒,音量大時旨在提醒對方注意,音量小則為掩飾自己的主旨或避免打擾第三者。重音所在則為個人的性向及目的。
三、音形:分子音及母音兩類,母音為主,子音為輔。母音長而循環,子音短而止於分別處。兹以英文拼音字母為例,一一説明如下:
a-母音,發“啊”音,口大張,喉管音,四到五組波形。
b-子音,發“白”音,唇爆音。
c-子音,發“塞”音,氣摩音。
d-子音,發“得”音,舌爆音。
e-母音,發“呃”音,口張舌收,喉管音,三到四組波形加顫波。
f-子音,發“弗”音,唇摩音,中頻風聲。
g-子音,發“哥”音,喉爆音。
h-子音,發“黑”音,喉風聲。
i-母音,發“衣”音,口收舌收,喉震音,二到三組波形加顫波。
k-子音,發“克”音,喉爆音加風聲。
l-子音,發“兒”音,捲舌收無鼻音。
m-子音,發“姆”音,全鼻音。
n-子音,發“嗯”音,收鼻音。
o-母音,發“歐”音,口張,喉管音,三到四組波形。
p-子音,發“皮”音,唇爆音加風聲。
r-子音,發“兒”音,捲舌。
s-子音,發“尸”音,高頻風聲。
t-子音,發“提”音,舌爆音加風聲。
u-母音,發“烏”音,口微張,喉管音,二到三組波形。
四、音色:音沿振盪、音波比例、音形特徵、子音比重等,皆可用來辨識個人之音色變化。加以適當的編碼,即可作為個體辨識。
五、音速:漢語正常發音約每秒鐘四音,舉凡音與音之間的空隙,母音的週期等,都是輔助辨識的重要依據。
語音除了辨識外,尚可合成,其法適為辨識之反向。
丙、形像
形像雖然是無窮無盡,但在系統分類下,倒也沒有多少類別。舉凡視線所及,不外乎光的明暗(光源編碼),環境範圍(分類編碼),主觀立場(透視編碼),物體邊緣(曲線編碼),體用因果(機能編碼)等。此外,再根據應用時的需求,作重點綜合處理,就能逐步化繁為簡,最後以簡馭繁了。
由編碼到合成,是一體的兩面。最理想的編碼方式,則是與漢字基因的理論結合,以字義理解作為形像的定義準則(下文解説中,將編碼與合成視為一體,不再分別解釋)。
一、三維影像
三維影像是根據任意系統之三維座標設計的,計有XYZ之座標值、顔色或材質貼圖、結構體之聯接關係、物質物性定義以及燈光環境的參數等。
根據XYZ座標值,可以畫出物體表面的標準網線,再加上主觀之鏡頭位置,即可得一虛擬的透視模型。
顔色及材質決定於視訊要求,例如模擬真實與卡通兩者效果相去甚遠,卡通只是一種簡易的表達方法,資料內容不變,然無法表現材質。
結構體在作部位運動時,需要根據其聯結關係,設定轉動軸點、方向、角度、限性、重心、摩擦等,由程式控制摹擬出接近真實的運動。
物質物性定義供碰撞、接觸、摩擦以及各種真實環境下的運動如飄動、浮動、移動、游動、滾動等計算之用。
燈光環境參數等提供戲劇效果或傳真效應,如燈光代表了室內或室外的氣氛條件,只要確定光源及光效,就可以節省大量的圖形處理手續。
二、形像編碼
形像編碼是視覺辨識的基本課題,只要將視覺基因設定為辨識參數,再以層次分類為輔,就能得到有效的形像編碼。
層次分類可參考概念分類(詳見《漢字基因》),兹以「電腦」一詞為例,説明如下:
上述編碼表僅分至三十二類,其類每類之下尚有八種,如11工作類下有:
000文具 001樂器 010工具 011農具 100武器 101機器 110材料 111廢料
物體經辨識後得到編碼,代碼可供貯存及傳輸。應用時再以三維繪圖,根據資料庫將編碼還原繪為圖形。這種工作可利用硬體處理,只要速度快,擬真度高,就有實用價值。以傳輸語言為例,人講話時,每秒鐘平均發出五個音節,祇需十個字元而已。
若用音潻傳送,至少需8k字元,再談圖形,其數量更難以估計。